
前言
这篇文章是与一个朋友闲聊时候的话题后来想着索性整理成文章为了让更多的同学理解人工智能的相关内容和常见算法思想我决定不使用公式或者代码尽量用一些简单通俗的例子但是这样必然有失准确性有什么问题可以在评论区里边讨论
社会进步在发展中部分领域呈现了令人惊异的相似性
前几天看到有群研究者整理了一份AI为了完成任务所耍了一些小心思觉着十分有趣摘抄两个小例子
问题检测X光片有无肺炎
程序实际检测的不是X光片的内容而是拍摄它使用的机器因为它发现病重的病人更可能在特定的医院使用特定的机器拍片Zechetal2018
问题检测皮肤癌
程序发现照片里皮肤病变的边上如果放了一把尺子那么这个病变就更可能是恶性的AndreEstevaetal2017
仔细一看这不就是江湖算命大pianzi师zi的套路嘛
如果你曾经了解过江湖算命这个行当会发现他们一个惯用的套路就是第一时间并不会问你所问何事会故作高深地凝视你一会然后得出几个结论问你他说的对不对
然后你会惊呼
你算得真准
本质上这个过程并不是算命而是观察和总结的能力
如是老年人问事业多半子女不孝
如是年轻人穿着破烂多是英雄迷途不知前路
如是年轻女性问十有八九是姻缘再看其神色则可知是热恋还是年轻人要闹分手了
从概率上讲这些论断八九不离十你也可以尽量朝坏了说毕竟一个人过得开心快乐生活幸福美满他是不会去算命的
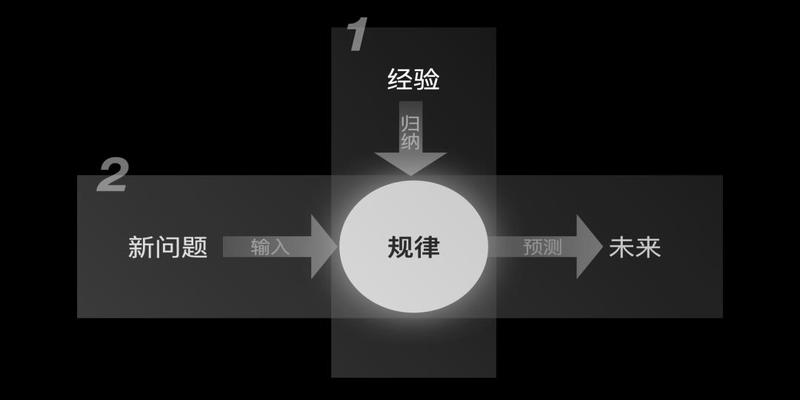
人类的学习和认知大部分结论是来自于经验总结根据历史和经验归纳出规律
当遇到新的问题的时候再根据总结出的规律进行预测
不过有趣的是人类从历史中得到的唯一教训就是人类从来不从历史中接受教训
相似的而机器学习不是基于推理的演绎法而是基于观测的归纳法
这个过程中使用算法处理历史数据在机器学习中叫做训练
训练得到的结果是一个关系这个关系可以描述历史数据也可以预测新的数据这个关系被称之为模型
机器学习MachineLearning
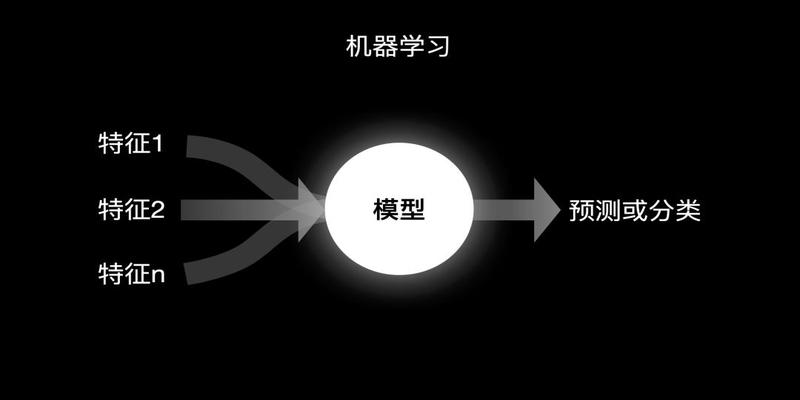
我们把经验和历史包含特征和结果这些数据扔给机器让他自动找出特征和结果之间的关系模型然后在利用这个模型进行预测和分类这个过程就是所谓的机器学习MachineLearning
华强买瓜线性回归LinearRegression
让我们来举一个小例子
有一个人前来买瓜

假如旁边有一个计算机他并不知道西瓜的价格他只能观察到称上的数字重量和付了多少钱价格
当有很多华强来买瓜这个计算机便收集了很多重量和价格的数据

我们把这些数据列出来计算机会从中找出一条规律其实就是找到一条线让这条线尽量经过所有数据点或者尽量离所有数据点最近
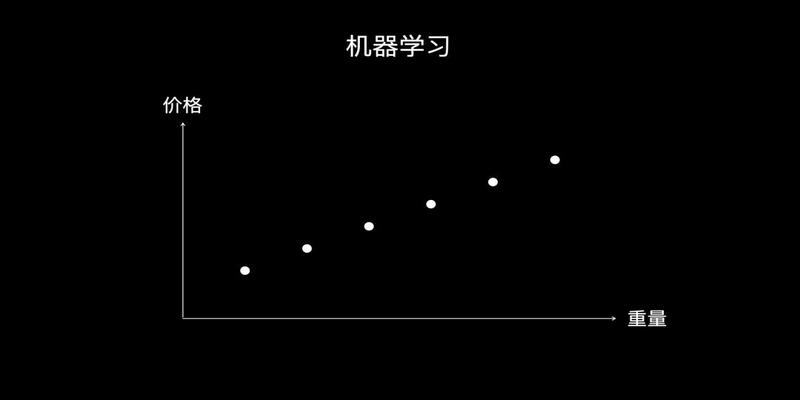
很快计算机就找到这条线用一个函数来表达
价格重量2
这个规律也就是商贩口中的两块钱一斤

如果还有人来买瓜计算机就可以根据这个规律来报出价格
当然这个是一个简单的线性模型也可以是其它类型的曲线比如抛物线或者指数关系机器学习有很多的算法比如最为经典的梯度下降算法这也就是我们所说的线性回归
当然也有能够进行非线性拟合的算法
打游戏吗决策树模型DecisionTree
还有一种经典的机器学习模型叫做决策树从上到下好像是一个开枝散叶的树
简单来说就是根据一层层的判断来做最终的决策或者分类
就拿周六要不要打游戏这件事情来说决策树模型如下
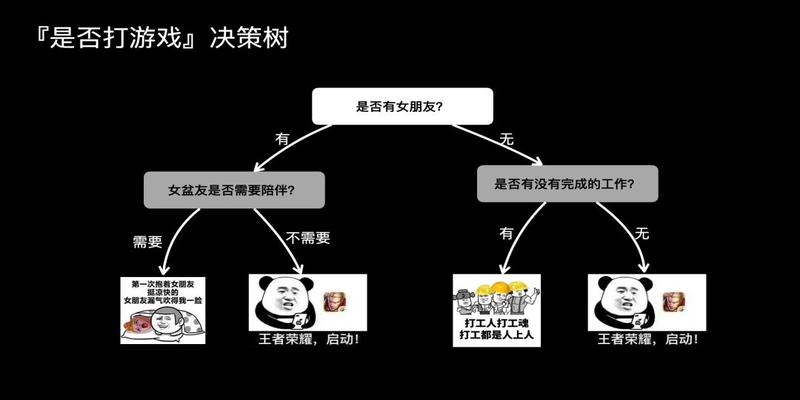
要不要打游戏这件事情受到多个变量的控制
取决于你有没有女朋友要陪取决于你有没有紧急的工作要完成
那么这个决策树是怎么来的来自于以往的经验和数据当把这些数据输入到计算机中就可以按照一定的算法生成决策树模型

当然以上的决策树是一个简单的模型大家可以看到有没有女朋友这个特征的重要性被过度放大了
假如你有女朋友但是你的女朋友不需要陪根据这个决策树你毅然决然的选择了打游戏但是有一项重要的工作你并没有完成周一上班老板肯定要砍了你的那种所以单一的决策树往往会造成偏差
女朋友比工作重要吗随机森林RandomForests
怎么解决呢可以通过随机挑选多个特征构建多个决策树之后再通过投票的方式来进行最终的决策这种方式被称之为随机森林RandomForests
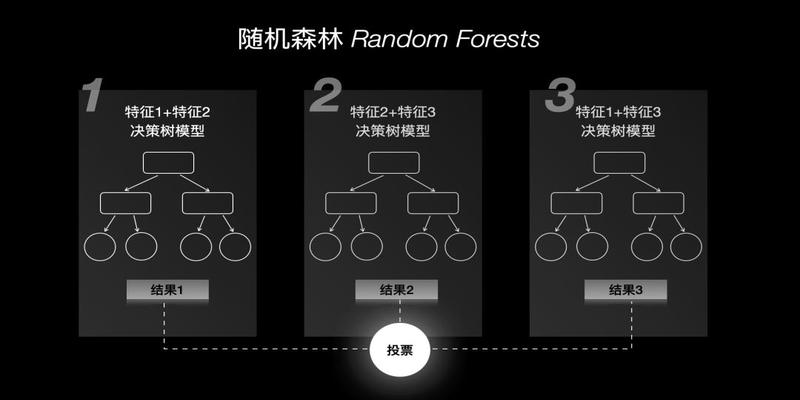
但是如果你精力旺盛好家伙同时交了八个女朋友因为每个女朋友脾气秉性对你的依赖程度也不尽相同随机森林这种随机挑选特征的方式有可能就会导致错误
交了八个女朋友梯度提升GradientBoosting
于是又诞生了梯度提升树
GBDT
思路步骤如下
1与随机森林不同的是并不是随机挑选特征来生成树梯度提升树采用了所有的特征来构建决策树
2然后把预测的结果与真实的结果进行比对计算出一个差值根据这个差值对于某些重要特征赋予权重建立新的决策树模型比如你给女友A赋予了更高的权重其它女友的权重甚至都没有工作重要
3不断的重复这个步骤就可以获得准确性更高的的决策树模型最终多个决策树模型的和就是最终结果
杨绛先生书中说
精通命理的对以往的事历历如绘不差分毫但推算将来则茫如捕风
机器学习也同样如此对于历史的数据太容易做拟合了只要你愿意每一个过往的数据都能给你拟合上做预测大部分都抓瞎了只能给出一个概率
这是因为什么呢大量的现实问题并不是重量价格这样明确的数字他们有可能不是数值有可能包含多个属性为了更好的量化他们所以很多时候我们需要给数据打标签其实人类在生活中很多的时候也下意识这么做会给人群打上标签地域黑00后五毛党海军米粉就是这么来的
可见数据越多模型就会越加的准确这也就是机器学习中数据为王的原因
你的数据标准更加全面更加准确无疑可以获得更加精确的结果
人工智能最为典型的应用图像识别内容归类疾病判断搜索推荐其实最基础的操作就是分类
分类的奥义
我是哪种人邻近算法KNNKNearestNeighbor
所谓K临近算法就是有K个最近的邻居的意思
思路也很简单
1计算一个新数据与已有数据的距离
2对距离进行排序选择距离最小的K个点
3对于K个点的属性进行查看把这个新数据归类到那个最多的类别中去
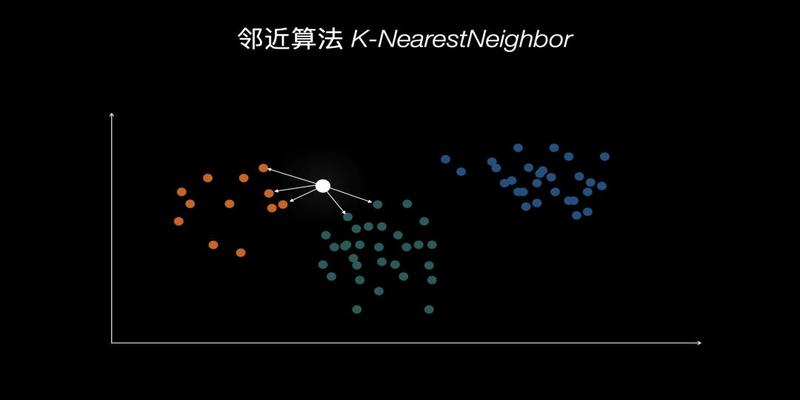
一个小例子假如只有两种学生一种勤奋苦学的一种是吊儿郎当的他们之间的差异是学习时间和抖音时长
历史数据如下
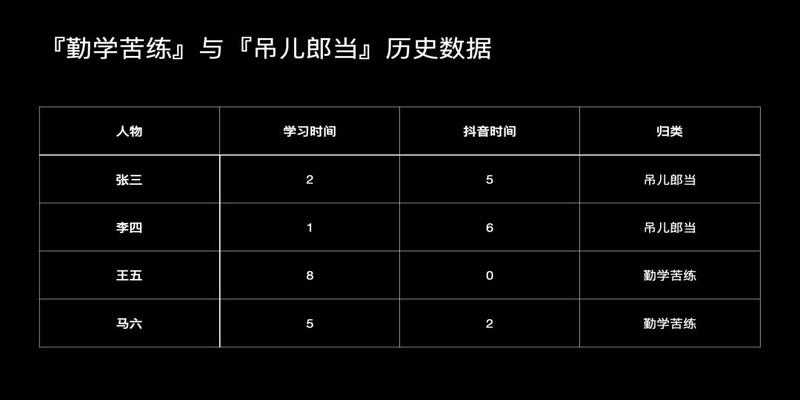
这时候有一个新人叫孙八学习时间3小时游戏时间5小时他属于那种类型的呢
做一下数据可视化我们一眼就可以看出孙八到底属于哪种类型

当然算法没有你这么好的眼力他还得老老实实的计算新数据每一个数据点的距离然后排个序
这时候我们只要统计前K个数据的标签是什么就知道新数据应该划分到那个类别
当然这个例子为了简化只用了时间一个维度的数据实际上KNN算法可以采取多个维度的数据计算距离的方式也多种多样最为常用的是欧氏距离
K的取值有时候也会影响结果的准确性
那么如何选择一个准确的K值呢
实际中并没有特别通用有效的解法只能是不断是尝试更换参数大家发现这个过程跟炼丹特别像加多少汞用多少炭完全不知道凭着感觉来爆炸了就更改下比例再来一次
于是调参也就被戏称为炼丹了

概率的概率贝叶斯分类器Bayesclassifier
所谓贝叶斯分类器主要原理就是贝叶斯定理
贝叶斯定理其实就算计算条件概率的公式指得就是在事件B发生的情况下事件A发生的概率
一个很简单的例子你经常在网上发一些自拍然后收到了很多私信那么大概率你是一个美女帅哥
这里边隐藏了一个经验概率就是我们认为好看的人比难看的人有更大概率收到私信这个概率被称之为先验概率
可以看到这个先验概率存在很大的主观性
而且实际生活中许多的事物是没有办法进行客观判断的到了互联网时代大数据和运算力为贝叶斯提供了基础只要数据量足够多这个先验概率也会不断的趋于准确
再举一个输入法的例子
如果你使用拼音输入法输入tianqi那么这个词语可能是天气田七天启
没有上下文的时候天气出现的概率要比田七多得多但是如果你前文出现了中药这两个字那么是这个词语田七的概率就会被天气大很多
为什么呢我们统计了之前大量的中文资料中药田七这个词组出现的概率要比中药天气多得多
贝叶斯分类器就是基于这样的原理来对新的数据进行分类
支持向量机SupportVectorMachine
支持向量机本质上也是一种逻辑回归算法根据已有数据用一条线作为数据集的分界线
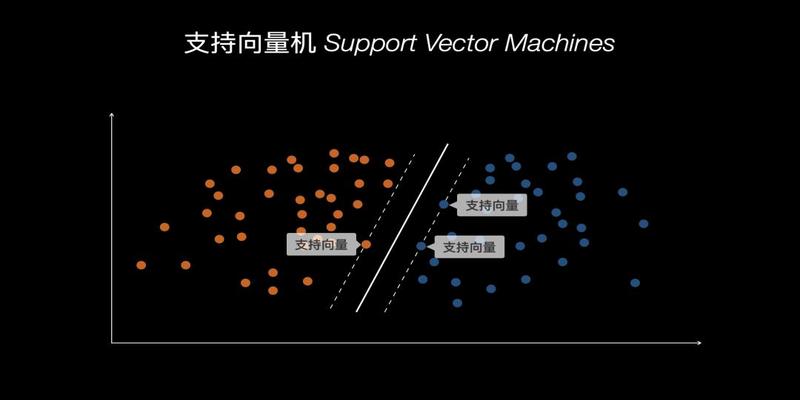
如图所示两条虚线是数据集的边界线其实这两条线也能作为两个数据集的分类但是明显精确度不高这时候我们需要算出两条线中间的那条实线也就是离已有数据越远越好这条分界的实线就被称为超平面
为什么一条线被称为平面呢这是因为目前我们的数据是二维的如果是三维的这条线就是一个面离超平面最近的数据点称之为支持向量
其实这样的分类线用逻辑回归方法也能画出来那么支持向量机的的优点在哪里
我们看这样的数据集

很明显是很难画出一条线将两类数据分开怎么做呢我们可以采用核函数这种数学手段把数据转换到高维度

这样我们就很容易画出这个超平面
未被标注的数据
以上所有的训练数据都经历过标注这些算法也被称之为监督学习
那么如果如果我们手头的数据没有标注如果通过这些数据来训练模型呢
这种不需要标注数据通过训练得到模型的算法称之为无监督学习
最为常见的就是聚类算法
K平均算法KMeans
步骤也很好理解
1将数据分为K组随机选择K个对象作为初始的聚类中心
2计算每个数据点到这聚类中心的距离
3按照距离把这些点分配给给对应的聚类中心
其实这就是一个近朱者赤近墨者黑的过程和人类自发组织的过程极其相似
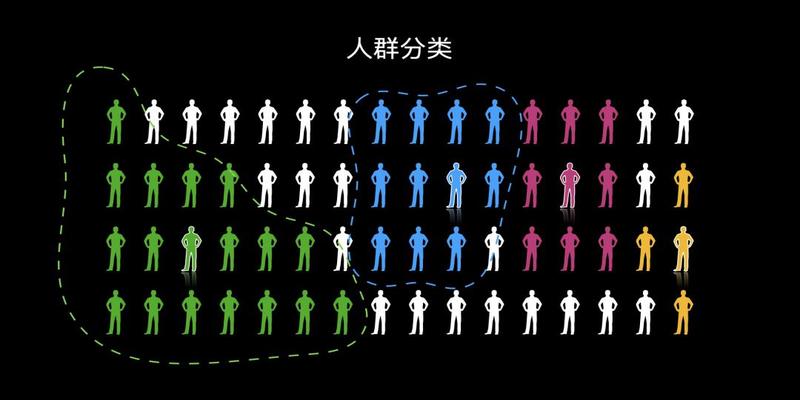
有一大群人接收到命令要分为若干个群体这时候肯定会有人自发站出来当小组长随机的聚类中心
然后人们会按照跟组长的相似性爱好习惯来决定跟定那个组计算距离归类
这时候组已经建成通过相互了解人们发现组里有一个人更加契合组长的要求然后推选他作为新的组长算法选出新的聚类中心
降维算法DimensionalityReduction
数据有多少维度
就拿你举例子吧关于你的数据有身高体重三围口味喜欢的电影在哪个大学读书历史观年收入喜欢的人是什么
种种数据要完全的形容你这个数据可以轻松松达到百维甚至千维
而每当增加一个维度时数据体积也就会指数级的增长以现在机器的处理能力根本没有办法应对这种情概况也被称之为维数灾难
那就降维打击吧
我们从一个现实的例子感受一下数据降维的过程
人与人之间的交往关系是特别复杂的
你请我吃过饭我帮你修过空调你曾经带我出去旅游我之前给你买过生日礼物你帮我内推过简历我帮你引荐了一个官员你给我推荐过股票我帮你挂了一个协和医院的专家号
那么如何衡量我们之间关系的好坏要把种种交往关系的过程数据化不是不可能只是数据量太多维度太高导致根本无法计算
那么有没有一种方法既可以减少分析的数据量又能够尽量的保留主要的信息
你肯定听过一句话成年人的世界只有利益
那么我们就可以把所有的交际过程转换成利益得失请吃饭多少钱修空调多少钱生日礼物多贵等等等都可以折合成金钱指标
这样原本多维的数据分析也就变成一维数据了分析起来自然明确而简单虽然有失精确但是起码能够对人际交往这种事情进行衡量了
这里只是为了数据降维举例不讨论人情世故
做错了就要挨揍强化学习Reinforcementlearning
上边提到的种种算法不论是监督学习还是无监督学习都需要原料也就是数据
没有数据的时候机器还能学习吗
答案是肯定的这种方法被称之为强化学习

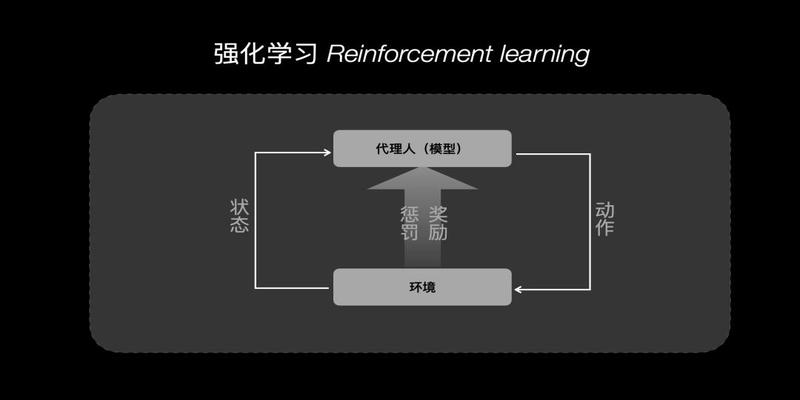
强化学习的原理也很简单
就是直接把模型丢到环境中模型会随机的进行操作环境会对操作做出反馈反馈就是惩罚或者奖励我们可以把反馈定义为加分或者减分
如果某种操作能够得到高分的话那么这个模型就会强化这个操作来获得更高的分数这也就是强化学习名称的的来由
我们假设有个孩子叫小明从来没追过女孩子也没看过什么爱情片总之对于恋爱这方面就是一张白纸无数据
但是年纪到了春心萌动他对班上的小红动了心他决定追小红于是就开始了各种操作动作小红也会对他的操作进行各种回复反馈
小红说他饿了小明于是采取了以下操作
买了两个大馒头给小红送了过去小红骂他你是沙雕吗惩罚减分
请小红吃海底捞然后小红给他发了一条信息今天晚上谢谢你哦奖励加分
小明在这个过程中发现请吃贵的高档的东西容易获得奖励于是他就强化了这个操作下一次直接请小红吃西餐强化策略的过程
当然实际的恋爱过程并不是这么简单
不同激励值的设置有可能会导致完全不同的结果上文的例子中如果只有请小红吃海底捞或者西餐才能获得加分其它操作都是减分小明很快就发现这样下去钱包根本扛不住所以小明毅然决然的选择了搞基这就不是我们想要的了
目前强化学习的应用主要在游戏方面比如打星际争霸的AlphaStar
让羊踢足球遗传算法GeneticAlgorithm
顾名思义就是模拟对生物进化的过程借鉴了达尔文和孟德尔的遗传学说
小明是个牧民养了一群羊有一天他突然奇想要让他的羊们学会踢足球
但是羊根本不知道什么是足球并且要把足球踢到门里去小明也懒得训练他们于是小明想了一个办法
随机找一群羊放到羊圈里并且给羊圈里安上球门放上足球
肯定有一部分羊对足球感兴趣会试着踢足球于是小明把那部分对足球不感兴趣的羊拿去烤了
留下来的羊开始生儿育女同样的做法不仅把对足球不感兴趣的羊弄死还有把踢不远的羊也弄死或者不让他们交配
这样很多代过去了留下了的羊就能把足球踢的越准越好了
实际中的遗传算法跟真正的遗传过程一样也有染色体基因选择变异种群的概念十分有意思感兴趣的可以深入了解一下
深度学习
神经网络neuralnetwork
既然称之为人工智能人们自然的想到一个问题
人类是如何思考和学习的呢
人们开始从生物学的角度研究大脑工作的原理
初中我们就学过了神经系统最为基础的结构就是神经元这里不妨复习一下

一个神经元就有多个树突用来接受外外接的消息
轴突只有一条用来整合从树突传来的消息
通过轴突末梢把信息传递给其他神经元
类似的我们把借用神经元这种结构翻译成计算机能够识别的模型就是以下这样也被称之为感知器

由于接受的信息的复杂了所以要给每个输入赋予一个权重也就是衡量这个信息重要程度的值
举个例子别人打了你一拳同时一滴雨落在你脸上还有一只蚊子要了你一口三个输入信息那么很显然打了一拳这个信息明显是最重要的赋予权重因为这个操作对你造成的伤害最大
而训练一个神经网络所谓的调参过程也就是在调整这些权重以使得最终的结果趋于准确
当很多的感知器分层次的连接起来的时候就形成了一个神经网络
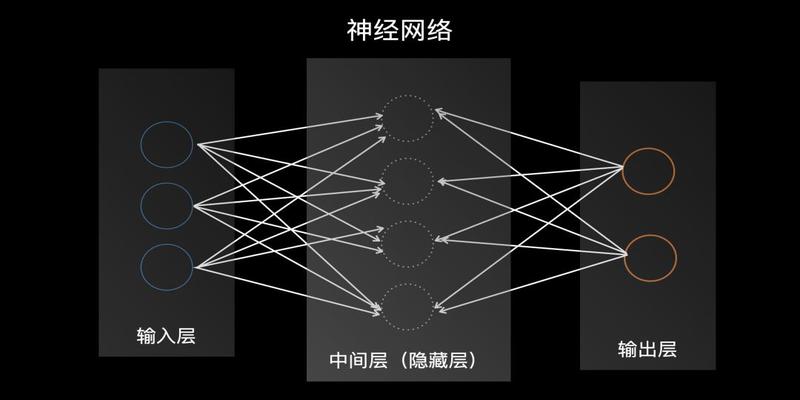
蓝色我们称之为输入层
虚线我们称之为中间层也被称之为隐藏层可以是单层也可以是多层
橙色的我们称之为输出层
中间的连线就是我们赋予的权重
目前你手机上的图片搜索识别甚至你抖音开的美颜滤镜无一不归功神经网络的发展
那么神经网络工作的原理是什么
首先我们把一大堆数据塞给输入层然后计算机会根据神经网络进行输出
将输出值与实际值进行比对算出一个差值根据这个差值反馈回去调节不同的权重
循环往复这个过程直到到达预期的目标
还是来一个简单的例子吧识别数字1
可以看到一共有20个输入每个输入代表不同的值涂色的我们可以用1代表没涂的可以用0代表
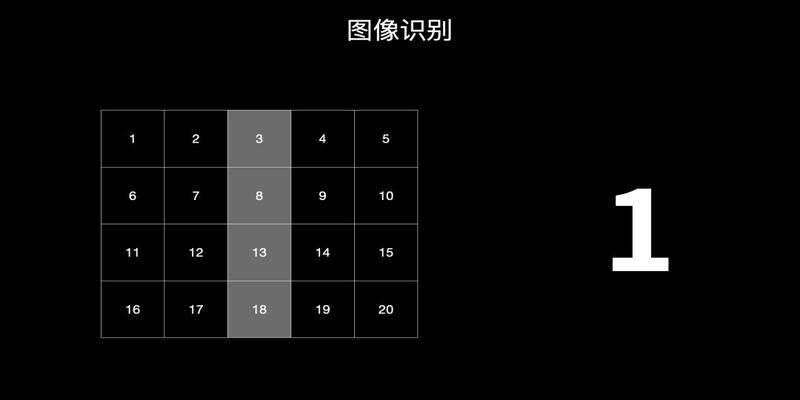
第一次训练的时候机器根据反馈很容易的给出了这20个不同输入的权重381318权重为100其它格子为0
但是输入了第二幅图实际的结果也是1
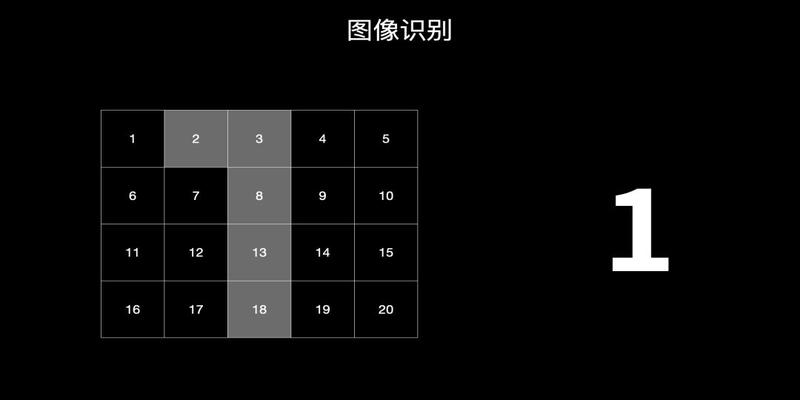
所以机器就将相关权重进行了调节比如将2的权重从0调整到50这样也能得到正确的结果
如此可以根据大量的数据整个模型在不断的自我优化过程中在成千上万次的训练中模型会变得越加的准确但是这个过程需要大量的运算这也也就是为什么之前机器学习的效果并不理想的原因算力不太够算法也不太聪明
后来又发展出了卷积神经网络CNN生成对抗神经网络GAN尤其是在图像处理领域上大放异彩
机器是否能够真的理解
这是一个长盛不衰的话题机器是否能够真的理解机器是否有意识以及机器是否能够预测
其实这个答案无关紧要
答案的关键就在于你怎么定义理解意识和预测
回到我们开头说到的算命有一句话说得好
你若信命一切偶然都是必然
你若不信一切必然都是偶然
问题是偶然的必然和必然的偶然有区别么
同样的
你认为的机器学习不过是数字的统计和矩阵的运算
那我也可以认为人类的情感和意识只不过是化学反应和神经电位的传播
你可以认为AlphaGo不理解围棋但是他就是打败柯洁
你可以认为GAN不懂梵高但是它能够轻松地把Starrynight的风格迁移到任何一副照片上

对于结果来说理解真的重要么或者还是说人类所谓的理解只不过是一厢情愿
不可否认的是虽然目前的人工智能还处于人工智障的状态但是他也在飞速的成长
在某些领域人工智能已经超越了人类人类智力最后的堡垒围棋也在5年前也被人工智能拿下了
还有一个不可忽视的问题就是人类有可能会看不懂人工智能神经网络的存在多个隐藏层的时候人们就无法理解其中的规律了层数越多结果越准确也就越难以解释
看不懂的后果的灾难性的因为你不知道他某一天会采取什么你意想不到的举措你还不知道怎么调节他因为压根不知道问题在哪
有朋友可能会说怕啥人类还有终极大招拉闸
这个从来都不是什么好的解法不信你看现在多少电站都是无人值守的了
那么对于人类来说最好的结局是什么
成为人工智能
毕竟只有魔法才能打败魔法













